[HW 1]영상처리 기본, Python & OpenCV
P1. (성능평가) 코로나 감염여부를 측정하는 방법으로 체온을 이용한다고 하다. 체온이 일정 수치 T 이상이면 코로나 감염으로 그렇지 않으면 정상인것으로 판단한다고 하자. 이 검사에 참가한 사람들 중 p 의 비율로 환자가, 1- p 의 비율로 정상인이 포함되어 있다고 가정하자. 환자는 체온 40도를 기준으로 표준편차 5의 정규분포를 따른다고 하고, 정상인은 35도를 기준으로 표준 편차 5의 정규분포를 따른다고 하자.
1) p = 0.5 인 경우 임의로 100명을 모집했을 때 (즉, 50명 씩) 두 집단의 체온을 정규 분포에 따라 랜덤 넘버를 생성하라.
<코드>
| import numpy as np positive = np.random.normal(40,5,50) negative = np.random.normal(35,5,50) |
<결과>

2) T 가 … 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, … 일 때의 혼동 매트릭스를 생성하라. 즉 TP, FP, TN, FN 를 각각 계산하라. (여기서 positive는 감염을 의미한다)
<코드>
| #판단기준 매트릭스 생성 Tem=np.array([30,31,32,33,34,35,36,37,38,39,40]) #혼동행렬 생성함수. 판단할 1차원 배열과 기준온도 T를 패러미터로 가진다. def makediffmatrix(pos,neg,T): #혼동행렬 모든원소 0으로 초기화 TP=0 FP=0 TN=0 FN=0 matrix=np.zeros((2,2)) #혼동행렬 저장용 2by2 행렬생성 x=0 #while문 인덱스 초기화 while (x<50): if(pos[x]>=T): TP=TP+1 #기준온도 T보다 높은 체온에 대해 감염으로 판단. x=x+1#while문 인덱스 증가 FN=50-TP #감염자가 총 50명이므로 FN=50-TP #비감염자에 대한 마찬가지 판단 반복수행 x=0 while (x<50): if(neg[x]>=T): FP=FP+1 x=x+1 TN=50-FP matrix[0,0]=TP matrix[0,1]=FN matrix[1,0]=FP matrix[1,1]=TN return TP,FN,FP,TN #최종적으로 혼동행렬을 리턴하고 함수종료 #혼동행렬 매트릭스 생성 diff=np.zeros((2,2,11)) print(diff) #혼동행렬 매트릭스에 값 부여 index=0 while(index<11): diff[0,0,index], diff[0,1,index], diff[1,0,index], diff[1,1,index] = makediffmatrix(positive, negative, index+30) index = index + 1 #각 혼동행렬 출력 index=0 while(index<11): print('confumatrix: ', 'T=', (index+30), 'TP=', diff[0,0,index], 'FN=' ,diff[0,1,index], 'FP=', diff[1,0,index], 'TN=', diff[1,1,index]) index = index + 1 |
<결과>

3) 위 결과를 사용하여 ROC를 그려라.
<코드>
| xaxis=np.zeros(11) yaxis=np.zeros(11) index=0 while(index<11): xaxis[index]=diff[1,0,index] / (diff[1,0,index]+diff[1,1,index]) yaxis[index]=diff[0,0,index] / (diff[0,0,index]+diff[0,1,index]) index=index+1 plt.plot(xaxis,yaxis) plt.show() |
<결과>

4) p = 0.2 인 경우에 대하여 위의 과정을 반복하여 보라.
<코드>
| ''' P1. (성능평가) 코로나 감염여부를 측정하는 방법으로 체온을 이용한다고 하다. 체온이 일정 수치 T 이상이면 코로나 감염으로 그렇지 않으면 정상인것으로 판단한다고 하자. 이 검사에 참가한 사람들 중 p 의 비율로 환자가, 1- p 의 비율로 정상인이 포함되어 있다고 가정하자. 환자는 체온 40도를 기준으로 표준편차 5의 정규분포를 따른다고 하고, 정상인은 35도를 기준으로 표준 편차 5의 정규분포를 따른다고 하자. 즉, 전체 확률 분포의 그림은 다음과 같은 형태를 띠게 될 것이다. ''' import numpy as np import matplotlib.pyplot as plt ''' 1) p = 0.5 인 경우 임의로 100명을 모집했을 때 (즉, 50명 씩) 두 집단의 체온을 정규 분포에 따라 랜덤 넘버를 생성하라 ''' positive = np.random.normal(40,5,20) negative = np.random.normal(35,5,80) print(positive) print(negative) ''' 2) T 가 … 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, … 일 때의 혼동 매트릭스를 생성하라. 즉 TP, FP, TN, FN 를 각각 계산하라. (여기서 positive는 감염을 의미한다) ''' #판단기준 매트릭스 생성 Tem=np.array([30,31,32,33,34,35,36,37,38,39,40]) #혼동행렬 생성함수. 판단할 1차원 배열과 기준온도 T를 패러미터로 가진다. def makediffmatrix(pos,neg,T): #혼동행렬 모든원소 0으로 초기화 TP=0 FP=0 TN=0 FN=0 matrix=np.zeros((2,2)) #혼동행렬 저장용 2by2 행렬생성 x=0 #while문 인덱스 초기화 while (x<20): if(pos[x]>=T): TP=TP+1 #기준온도 T보다 높은 체온에 대해 감염으로 판단. x=x+1#while문 인덱스 증가 FN=20-TP #감염자가 총 20명이므로 FN=50-TP #비감염자에 대한 마찬가지 판단 반복수행 x=0 while (x<80): if(neg[x]>=T): FP=FP+1 x=x+1 TN=80-FP matrix[0,0]=TP matrix[0,1]=FN matrix[1,0]=FP matrix[1,1]=TN return TP,FN,FP,TN #최종적으로 혼동행렬을 리턴하고 함수종료 #혼동행렬 매트릭스 생성 diff=np.zeros((2,2,11)) print(diff) #혼동행렬 매트릭스에 값 부여 index=0 while(index<11): diff[0,0,index], diff[0,1,index], diff[1,0,index], diff[1,1,index] = makediffmatrix(positive, negative, index+30) index = index + 1 #각 혼동행렬 출력 index=0 while(index<11): print('confumatrix: ', 'T=', (index+30), 'TP=', diff[0,0,index], 'FN=' ,diff[0,1,index], 'FP=', diff[1,0,index], 'TN=', diff[1,1,index]) index = index + 1 ''' 3) 위 결과를 사용하여 ROC를 그려라. ''' xaxis=np.zeros(11) yaxis=np.zeros(11) index=0 while(index<11): xaxis[index]=diff[1,0,index] / (diff[1,0,index]+diff[1,1,index]) yaxis[index]=diff[0,0,index] / (diff[0,0,index]+diff[0,1,index]) index=index+1 plt.plot(xaxis,yaxis) plt.show() |
<결과>



P2. [이미지포맷] 실습에서 사용한 imwrite 함수를 사용한 png와 jpeg 저장에 대하여 좀더 공부해보자.
1) IMWRITE_PNG_COMPRESSION 옵션에 대하여 조사하고 옵션값을 변화시기면서 결과를 확인 해보라. 그 결과에 대하여 설명하라.
<결과>
JPEG와 달리 PNG의 경우 옵션값을 다르게 설정하여도 각 저장된 이미지에서 육안으로 확인 가능한 화질 차이는 발생하지 않았고, 더 정확한 비교를 위해 옵션값을 0,10,100으로 변화시키면서 아래의 코드를 실행시켰다.
| import cv2 import numpy as np imgfilePath = 'Lena.png' #불러온 이미지 img = cv2.imread(imgfilePath) outpngfile = 'Lenna_compressed.png' outjpgfile = 'Lenna_compressed.jpg' #PNG 저장 cv2.imwrite(outpngfile, img, [cv2.IMWRITE_PNG_COMPRESSION, 10]) png_img = cv2.imread(outpngfile) #PNG로 저장한 파일 불러오기 tmp = (png_img == img) print(tmp.all()) |
하지만 모든 옵션값의 경우에서 마지막 코드는 항상 True를 출력하였고, 이를 통해 IMWRITE_PNG_COMPRESSION 의 옵션값은 이미지 화질에 영향을 주지 않는다는 것을 확인하였다.
다만 옵션값 0 지정시 저장된 파일의 크기가 770kb, 옵션값 50 지정시 442kb, 옵션값 51 이상 지정시 442kb로 파일 크기에 변화가 없는 걸로 보아 IMWRITE_PNG_COMPRESSION의 옵션값은 0~50의 범위에서 의미가 있으며 옵션값은 파일의 크기(즉 압축률)에 관여한다고 볼 수 있다.
2) IMWRITE_JPEG_QUALITY 옵션에 대하여 조사하고 옵션값을 변화시기면서 결과를 확인 해보라. 그 결과에 대하여 설명하라.
<결과>
 |
 |
 |
| [cv2.IMWRITE_JPEG_QUALITY, 100] | [cv2.IMWRITE_JPEG_QUALITY, 10] | [cv2.IMWRITE_JPEG_QUALITY, 0] |
옵션값을 순서대로 100,10,0으로 설정하였을 때 확연한 화질의 차이를 볼 수 있다.
IMWRITE_JPEG_QUALITY는 이미지를 jpeg 포맷으로 압축하여 저장할 때 이미지의 퀄리티를 조절해주는 옵션이다.
P3. [color space] 컬러 스페이스에 대한 내용이다.

1) 다음 사진처럼 각 색상 별 영역이 50x50화소가 되도록 numpy 배열을 생성하고 이를 화면에 출력하는 프로그램을 자하여 생성해보라. 각 색상은 첫 줄은 Black,Red, Green, Blue이고 두번째 줄은 White, Cyan, Yellow, Magneta이다.
<코드>
| import numpy as np import cv2 img=np.zeros([100,200,3]) #BGR 순서 #1행1열 img[:50,:50,0]=0 img[:50,:50,1]=0 img[:50,:50,2]=0 #1행2열 img[:50,50:100,0]=255 img[:50,50:100,1]=0 img[:50,50:100,2]=0 #1행3열 img[:50,100:150,0]=0 img[:50,100:150,1]=255 img[:50,100:150,2]=0 #1행4열 img[:50,150:200,0]=0 img[:50,150:200,1]=0 img[:50,150:200,2]=255 #2행1열 img[50:100,:50,0]=255 img[50:100,:50,1]=255 img[50:100,:50,2]=255 #2행2열 img[50:100,50:100,0]=255 img[50:100,50:100,1]=255 img[50:100,50:100,2]=0 #2행3열 img[50:100,100:150,0]=0 img[50:100,100:150,1]=255 img[50:100,100:150,2]=255 #2행4열 img[50:100,150:200,0]=255 img[50:100,150:200,1]=0 img[50:100,150:200,2]=255 cv2.imshow("COLOR", img) k = cv2.waitKey(5000) |
<결과>

2) 위의 내용을 opencv 함수를 사용하여 Gray 이미지로 변환하고 화면에 출력하라. 각 컬러들이 어떤 값을 갖는지도 확인하여 적어라.
<코드>
| import matplotlib.pyplot as plt #원본이미지 저장 cv2.imwrite('colorpalete.png', img, [cv2.IMWRITE_PNG_COMPRESSION, 0]) plt.imshow(img) plt.title('color imeage') plt.show() #GRAY 이미지로 변환 grayimg = cv2.imread('colorpalete.png', cv2.IMREAD_GRAYSCALE) cv2.imwrite('gray.png', grayimg, [cv2.IMWRITE_PNG_COMPRESSION, 0]) graypalete = cv2.imread('gray.png') plt.imshow(graypalete) plt.title('gray imeage') plt.show() #gray 이미지의 각 밝기값 확인하기. #1행 색상 print(grayimg[25,25]) print(grayimg[25,75]) print(grayimg[25,125]) print(grayimg[25,175]) print('') #2행 색상 print(grayimg[75,25]) print(grayimg[75,75]) print(grayimg[75,125]) print(grayimg[75,175]) |
<결과>

각 부분의 컬러들은 아래와 같은 밝기값을 가진다. 순서대로 1행 원소, 2행 원소이다.
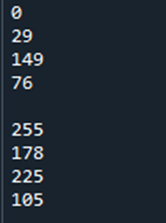
3) 위 Gray 로 변환된 결과를 보고 RGB채널값과 gray (명도) 값의 상관관계를 유추해보라.
각 부분의 Gray값과 R,G,B 값을 비교해본 결과는 다음과 같다:

위의 결과로부터 GRAY=R*(76/255)+G*(149/255)+B*(29/255)의 관계에 따라 변환되는 것을 알 수 있다.
4) 다시 원 영상을 RGB 영상을 HSV로 변환한 후 색상값이 어떻게 변환이 됬는지 확인하여 적어라. 위 변환 결과는 수업시간에 배운 공식과 일치하는가?
변환결과 각 채널(VSH 순서)의 값은 다음과 같았고:

수업시간에 배운 공식과 달리 S, V 값이 [0,1]이 아닌 [0,255]범위에 있었다.
P4. (speedup) 영상 처리를 하는 경우, 데이터를 반복문을 사용하여 원소 단위로 처리하게 되면 스크립트 방식으로 처리되므로 계산 시간이 오래 걸린다. 이를 해결하기 위한 방식이 벅터화 연산이다. Numpy는 벡터화를 지원하기위하여 원소 접근의 index 방식과 broadcasting 등을 지원한다. 수업에서 배운 방식을 이용하여 다음을 가속하여 보라.
| Element-wise | Vector-wise |
|
다음은 입력 영상을 명도값 T을 기준으로 이진화여여 출력하는 함수이다.
import cv2 import numpy as np import time T = 100 im_bgr = cv2.imread('../kame/data/Lena.png') if im_bgr is None: print('Cannot find file') exit() im_gray = cv2.cvtColor(im_bgr, cv2.COLOR_BGR2GRAY) im_bin = np.zeros_like(im_gray) start_time = time.time() for v in range(im_gray.shape[0]): for h in range(im_gray.shape[1]): if im_gray[v,h] > T: im_bin[v,h] = 255 print("ex-time 1:",time.time()-start_time) cv2.imwrite('output1.jpg', im_bin) |
import cv2
import numpy as np import time def Accelate(): T = 100 im_bgr = cv2.imread('Lena.png') if im_bgr is None: print('Cannot find file') exit() im_gray = cv2.cvtColor(im_bgr, cv2.COLOR_BGR2GRAY) im_bin = np.zeros_like(im_gray) start_time = time.time() bool_inx = (im_gray > T) #im_gray 어레이에서 T 초과인 인덱스에 대해 True 부여 im_bin[bool_inx] = 255 #해당 True 인덱스에 대해 동일한 작업 수행 print("ex-time_vector:",time.time()-start_time) #실행시간측정 cv2.imwrite('output_vector.jpg', im_bin) Accelate() |
<비교결과>
아래와 같은 전체 코드를 실행하였고
| ''' (speedup) 영상 처리를 하는 경우, 데이터를 반복문을 사용하여 원소 단위로 처리하게 되면 스크립트 방식으로 처리되므로 계산 시간이 오래 걸린다. 이를 해결하기 위한 방식이 벅터화 연산이다. Numpy는 벡터화를 지원하기위하여 원소 접근의 index 방식과 broadcasting 등을 지원한다. 수업에서 배운 방식을 이용하여 다음을 가속하여 보라. ''' import cv2 import numpy as np import time #Original code def Original(): T = 100 im_bgr = cv2.imread('Lena.png') if im_bgr is None: print('Cannot find file') exit() im_gray = cv2.cvtColor(im_bgr, cv2.COLOR_BGR2GRAY) im_bin = np.zeros_like(im_gray) start_time = time.time() for v in range(im_gray.shape[0]): for h in range(im_gray.shape[1]): if im_gray[v,h] > T: im_bin[v,h] = 255 print("ex-time_list:",time.time()-start_time) cv2.imwrite('output1.jpg', im_bin) def Accelate(): T = 100 im_bgr = cv2.imread('Lena.png') if im_bgr is None: print('Cannot find file') exit() im_gray = cv2.cvtColor(im_bgr, cv2.COLOR_BGR2GRAY) im_bin = np.zeros_like(im_gray) start_time = time.time() bool_inx = (im_gray > T) #im_gray 어레이에서 T 초과인 인덱스에 대해 True 부여 im_bin[bool_inx] = 255 #해당 True 인덱스에 대해 동일한 작업 수행 print("ex-time_vector:",time.time()-start_time) #실행시간측정 cv2.imwrite('output_vector.jpg', im_bin) Original() Accelate() |
실행 결과는 다음과 같았다:

동일한 연산을 수행하는데 확연한 실행시간의 차이가 나타났다.
참고 자료

컴퓨터 비전(Computer Vision)
기본 개념부터 최신 모바일 응용 예까지-
저자오일석
-
출판한빛아카데미
-
출간2014.07.30.